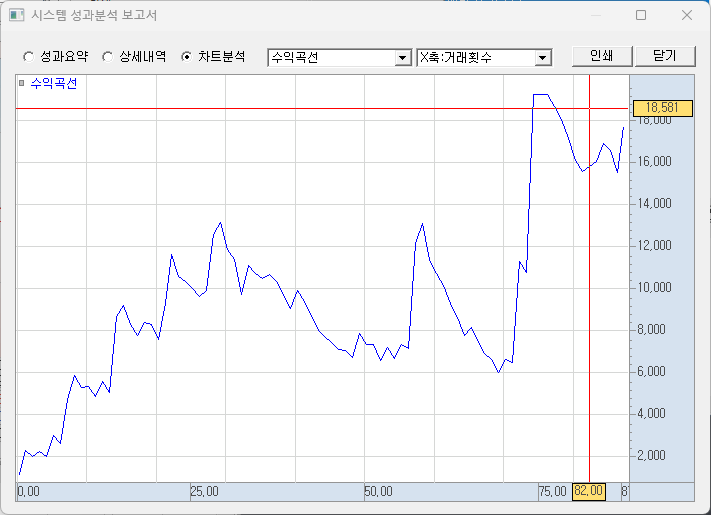
코스닥 시가 고평가의 미스테리 : 네이버 블로그 (naver.com) 카지노 개장 효과. 왜 코스닥은 시가에 비쌀까? 코스닥이 시가에 비싼 효과가 얼마나 지배적이냐면, 종가에 매수 다음날 시가에 매도를 반복하면 돈이 콸콸 벌릴 정도다. 누군가 시가에 꾸준히 사고 있다는 것이다. 단순한 엑셀 백테스트로도 확인할 수 있지만 더 복잡하게 패턴 인식을 해봐도 코스닥의 장중 움직임은 우하향세다. 시가에 많이 오르고 오후에 빠지기를 반복하며, 시가 상승폭이 전체 코스닥 시장의 상승폭을 대부분 설명하고 있다. 제정신인 사람이라면 코스닥을 시가에 사면 안된다. 장중이나 종가에 사는 것이 장기적으로 무조건 유리하다. 또한 다음날 아침에 기회가 된다면 팔아버리고, 다시 오후나 종가에 재매수하는게 유리하다. 시가의 고평가가..