https://earthconquest.tistory.com/61
[SQLD] 24. 그룹 함수 (GROUP FUNCTION)
1. 데이터 분석 개요 ANSI/ISO SQL 표준은 데이터 분석을 위해서 세 가지 함수를 정의함 1) AGGREGATE FUNCTION 2) GROUP FUNCTION 3) WINDOW FUNCTION 가) AGGREGATE FUNCTION GROUP AGGREGATE FUNCTION ( COUNT,..
earthconquest.tistory.com
1. 데이터 분석 개요
- ANSI/ISO SQL 표준은 데이터 분석을 위해서 세 가지 함수를 정의함
1) AGGREGATE FUNCTION 2) GROUP FUNCTION 3) WINDOW FUNCTION
가) AGGREGATE FUNCTION
- GROUP AGGREGATE FUNCTION ( COUNT, SUM, AVG, MAX, MIN 외 각종 집계 함수 )
나) GROUP FUNCTION
- 결산 개념의 업무를 가지는 원가나 판매 시스템의 경우는 소계, 중계, 합계, 총 합계 등 여러 레벨의 결산
- 그룹 함수를 사용한다면 하나의 SQL 로 테이블을 한 번만 읽어서 빠르게 리포트 작성 가능
- ROLLUP 함수 : 소그룹 간의 소계를 계산, 사용이 쉽고, 병렬 수행 가능
- CUBE 함수 : GROUP BY 항목들간 다차원적인 계산, 다양한 데이터를 얻는 장점, But 시스템 부하 많은 단점
- GROUPING SETS : 특정 항목에 대한 소계를 계산
- ROLLUP, CUBE, GROUPING SETS 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 정렬 칼럼을 명시
다) WINDOW FUNCTION
- 분석함수(ANALYTIC FUNCTION)나 순위 함수(RANK FUNCTION)를 말함
GROUP BY FUNCTION 설명
링크 : http://scidb.tistory.com/search/group%20by%20extension
A. ROLLUP : 오른쪽부터 GROUP BY 칼럼을 삭제 하여 집합을 계속 생성 하라
- GROUP BY 컬럼 갯수 + 1 만큼 집합이 강제로 생성
SELECT A,B, SUM(C)
FROM T
GROUP BY ROLLUP (A,B)
==>
SELECT A,B, SUM(C)
FROM T
GROUP BY A,B
UNION ALL
SELECT A,NULL, SUM(C)
FROM T
GROUP BY A
UNION ALL
SELECT NULL,NULL SUM(C)
FROM T
GROUP BY NULLB. CUBE : 나올 수 있는 모든 경우의 GROUP BY 절을 생성 하라.
- 2의 N승(GROUP BY 컬럼갯수) 만큼 집합이 강제로 생성
SELECT A,B, SUM(C)
FROM T
GROUP BY CUBE(A,B)
==>
SELECT NULL, NULL, SUM(C)
FROM T
GROUP BY NULL
UNION ALL
SELECT NULL, B, SUM(C) << ROLLUP(A,B) 에 없는 경우의 수
FROM T
GROUP BY B
UNION ALL
SELECT A, NULL, SUM(C)
FROM T
GROUP BY A
UNION ALL
SELECT A, B, SUM(C)
FROM T
GROUP BY A, B
C. GROUPING SETS : comma(,)를 UNION 으로 바꿔서 GROUP BY 절을 계속 생성 하라.
- COMMA 로 분리된 GROUP BY 절의 컬럼수 만큼 집합이 생성
SELECT A,B, SUM(C)
FROM T
GROUP BY
GROUPING SETS (A,B )
==>
SELECT A, NULL, SUM(C)
FROM T
GROUP BY A
UNION ALL
SELECT NULL, B, SUM(C)
FRO T
GROUP BY B
2. ROLLUP 함수
- ROLLUP 에 지정된 Grouping Columns 의 List는 Subtotal(소계)을 생성하기 위해 사용함
- Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal 이 생성됨
- ROLLUP 의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀌게 되므로 인수의 순서에도 주의 필요
* STEP 1. 일반적인 GROUP BY 절 사용 *
부서명과 업무명을 기준으로 사원수와 급여 합을 집계한 일반적인 GROUP BY SQL * Oracle 과거 버전에서 GROUP BY 사용지 자동 정렬은 더이상 지원 되지 않는다. ==> 명시적 정렬 필요
SQL>
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY DNAME, JOB ;
STEP 1-2. GROUP BY 절 + ORDER BY 절 사용 *
부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에 ORDER BY 절 사용함으로써 부서, 업무별로 정렬
SQL>
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY DNAME, JOB
ORDER BY DNAME, JOB ;
* STEP 2. ROLLUP 함수 *
부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에 ROLLUP 함수 사용
SQL>
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB) ;
* STEP 2-2. ROLLUP 함수 + ORDER BY 절 사용 *
부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에 ROLLUP 함수 사용
* 추가로 ORDER BY 절 사용해서 부서, 업무별로 정렬
SQL>
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB)
ORDER BY DNAME, JOB ;
* STEP 3. GROUPING 함수 사용 : ROLLUP, CUBE, GROUPING SETS 등 새로운 그룹 함수를 지원하기 위해 GROUPING 함수가 추가됨
* ROLLUP 이나 CUBE 에 의한 소계가 계산된 결과에는 GROUPING(EXPR) = 1 로 표시
* 그 외의 결과에는 GROUPING(EXPR) = 0 이 표시된다.
* GROUPING 함수와 CASE/DECODE 를 이용해, 소계를 나타내는 필드에 원하는 문자열을 지정할 수 있음(Report 작성시 )
SQL>
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB) ;
* STOP 4. GROUPING 함수 + CASE 사용 [ Reporting 용도 ]
SQL>
SELECT CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB) ;
* DECODE 로 표현
SQL>
SELECT DECODE(GROUPING(DNAME),1,'All Departments',DNAME) AS DNAME,
DECODE(GROUPING(JOB),1, 'All Jobs',JOB) AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB) ;
=> 그런데, reporting 용도로는 nvl이 더 편하다. 이렇게:
nvl(job, 'All Jobs')
* STEP 4-2. ROLLUP 함수 일부 사용
* GROUP BY ROLLUP(DNAME,JOB) 조건에서 GROUP BY DNAME, ROLLUP(JOB) 조건으로 변경
SQL>
SELECT DECODE(GROUPING(DNAME),1,'All Departments',DNAME) AS DNAME,
DECODE(GROUPING(JOB),1, 'All Jobs',JOB) AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, ROLLUP(JOB) ;
* STEP 4-3. ROLLUP 함수 결합 컬럼 사용
* JOB 과 MGR는 하나의 집합으로 간주하고, 부서별, JOB & MGR 에 대한 ROLLUP 결과를 출력
SQL>
SELECT DNAME, JOB, MGR, SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, (JOB,MGR)) ;

3. CUBE 함수
- ROLLUP 에서는 단지 가능한 SUBTOTAL만을 생성하였지만, CUBE는 결합 가능한 모든 값에 대하여 다차원 집계를 생성
- 모든 결한 가능한 경우의 수를 구하므로, 인수의 순서 변경되어도 상관없음
- 정렬이 필요한 경우는 ORDER BY 절에 명시적으로 정렬
* STEP 5. CUBE 함수 이용
* GROUP BY ROLLUP(DNAME, JOB) ==> GROUP BY CUBE(DNAME, JOB)
* 2의 N승(GROUP BY 컬럼갯수) 만큼 집합이 강제로 생성 ==> 4가지 경위에 대한 UNION ALL 을 의미하는 듯
SQL>
SELECT CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE(DNAME, JOB) ;
* STEP 5-2. UNION ALL 사용 SQL
* CUBE 와 같은 결과를 UNION ALL 로 구현
* 결과 데이타는 같으나 행들의 정렬은 다를 수 있음
* CUBE 의 장점 : UNION ALL 과 다르게 테이블을 한번만 Access
SQL>
SELECT DNAME, JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
SELECT DNAME, 'ALL JOBS', COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'ALL DEPERTMENTS', JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB
UNION ALL
SELECT 'ALL DEPERTMENTS', 'ALL JOBS', COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO ;
4. GROUPING SETS 함수
- GROUPING SETS 를 이용해 더욱 다양항 소계 작성
- GROUPING BY SQL 문장을 여러 번 반복하지 않아도 원하는 결과를 얻을 수 있다.
- GROUPING SETS 함수에 대한 정렬이 필요한 경우 ORDER BY 명시
- GROPUING SETS 함수는 인수의 순서가 바뀌어도 상관없음 ( 하단 예시 참조 )
* 일반 그룹함수를 이용한 SQL
* 부서별, JOB 별 인원수와 급여 합
SQL>
SELECT DNAME, 'ALL JOBS' JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'ALL DEPARTMENTS' DNAME, JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB ;
* GROUPING SETS 사용 SQL
SQL>
SELECT DECODE(GROUPING(DNAME), 1,'ALL DEPARTMENTS', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1,'ALL JOBS' , JOB ) AS JOB,
COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS ( DNAME, JOB ) ; 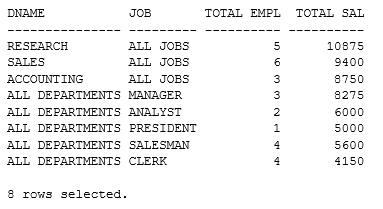
* GROUPING SETS 사용 SQL - 순서 변경
* 일반 그룹함수를 GROUPING SETS 함수로 변경하여 부서별, JOB별 인원수와 급여 합을 구하는데 GROUPING SETS 의 인수들의 순서를 변경
* GROUPING SETS 인수들은 평등한 관계이므로 인수의 순서과 바뀌어도 결과는 같다.
SQL>
SELECT DECODE(GROUPING(DNAME), 1,'ALL DEPARTMENTS',DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1,'ALL JOBS',JOB) AS JOB,
COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP,DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS ( JOB, DNAME ) ; 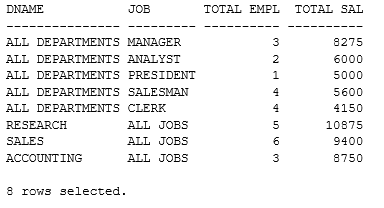
* 3개의 인수를 이용한 GROUPING SETS 이용
* 부서-JOB-매니저 별 집계와, 부서-JOB 별 집계와, JOB-매니저 별 집계를 GROUPING SETS 함수를 이용해서 구현
SQL>
SELECT DNAME, JOB, MGR, SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (( DNAME, JOB, MGR), (DNAME, JOB), ( JOB,MGR));
정리
/*
------그룹함수
----1. 소개: 소그룹 간의 소계를 계산하는 ROLLUP함수, GROUP BY항목들 간 다차원적인 소계를 계산할 수 있는 CUBE함수,
특정 항목에 대한 소계를 계산하는 GROUPING SETS함수가 있다.
ROLLUP은 GROUP BY의 확장된 형태로 사용하기 쉬우며 병렬로 수행이 가능하기 때문에 효과적이다.
CUBE는 결합 가능한 모든 값에 대해 다차원적인 집계를 생성하게 되므로 ROLLUP에 비해 다양한 데이터를 얻는 반면
시스템에 부하를 많이 준다.
GROUPING SETS은 원하는 부분의 소계만 손쉽게 추출할 수 있는 장점이 있다.
----2. ROLLUP함수
ROLLUP에 지정된 GROUPING COLUMNS의 LIST는 SUBTOTAL을 생성하기 위해 사용되어지며,
GROUPING COLUMNS의 수를 N이라고 했을 때 N+1 LEVEL의 SUBTOTOAL이 생성된다.
중요한 것은 ROLLUP의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행결과도 바뀌에 되므로 인수의 순서에 주의하자.
이제 ROLLUP과 CUBE의 효과를 알아보자
*/
--가. 일반적인 GROUP BY절 사용
--부서명과 업무명을 기준으로 사원수와 급여 합을 집계한 일반적인 GROUP BU SQL문장을 수행한다.
SELECT DNAME, JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB;
--가. 1. GROUP BY절 + ORDER BY절
SELECT DNAME, JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
ORDER BY 1, 2;
--나. ROLLUP함수 사용
SELECT DNAME, JOB, COUNT(*) "TOTAL EMPL", SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
--실행결과에서 2개의 GROUPING COLUMNS(DNAME, JOB)에 대하여 추가 LEVEL의 집계가 생성되었다.
--L1: GROUP BY 수행시 생성되는 표준 집계 / L2: DANME별 모든 JOB의 SUBTOTAL / L3: GRAND TOTAL
--나. 1. ROLLUP함수 + ORDER BY절
SELECT DNAME, JOB, COUNT(*) "TOTAL EMPL", SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB)
ORDER BY 1, 2;
--다. GROUPING 함수 사용
/*
ROLLUP, CUBE, GROUPING SETS 등 새로운 그룹 함수를 지원하기 위해 GROUPING함수가 추가되었다.
ROLLUP이나 CUBE에 의한 소계가 계산된 결과에는 GROUPING(EXPR)=1이 표시되고,
그 외의 결과에는 GROUPING(EXPR)=0이 표시된다.
GROUPING 함수와 CASE/DECODE를 이용해, 소계를 나타내는 필드에 원하는 문자열을 지정할 수 있어서 보고서작성이 유리하다.
*/
--아래는 ROLLUP함수를 추가한 집계보고서에서 집계 레코드를 구분할 수 있는 GORUPING함수가 추가된 SQL이다.
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB);
/*
--라. GROUPING 함수 + CASE 사용
ROLLUP함수를 추가한 집계보고서에서 집계레코드를 구분할 수 있는 GROUPING함수와 CASE함수를 함께사용한다.
*/
SELECT CASE GROUPING(DNAME) WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB) WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
--라 2. ROLLUP함수 일부 사용
--GROUP BY DNAME, ROLLUP(JOB)조건으로 사용한 경우이다.
SELECT CASE GROUPING(DNAME) WHEN 1
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB) WHEN 1
THEN 'All Jobs'
ELSE JOB
END AS JOB, COUNT(*) "TOTAL EMPL", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, ROLLUP (JOB);
--이 결과는 라. 결과에서 마지막 행이 출력되지 않음을 알 수 있다. 이는 ROLLUP함수가 JOB컬럼에만 사용되었기 때문이다.
--라. 3. ROLLUP함수 결합 컬럼 사용
--JOB과 MGR는 하나의 집합으로 간주하고, 부서별, JOB&MGR에 대한 ROLLUP 결과를 출력한다.
SELECT DNAME, JOB, MGR, SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, (JOB, MGR));
/*
----3. CUBE함수
ROLLUP에서는 단지 가능한 Subtotal만을 생성했지만, CUBE는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다.
CUBE를 사용할 경우에는 내부적으로 Grouping Columns의 순서를 바꾸어서 또 한 번의 쿼리를 추가 수행햐아 한다.
뿐만 아니라 Grand Total은 양쪽의 쿼리에서 모두 생성이 되므로 한 번의 쿼리에서는 제거되어야한 하므로 ROLLUP에 비해
시스템의 연산 대상이 많다.
이처럼 Grouping Columns이 가질 수 있는 모든 경우에 대하여 Subtotal을 생성해야 하는 경우에는 CUBE를 사용하는 것이
좋으나 ROLLUP에 비해 시스템에 많은 부담을 주므로 사용에 주의해야 한다.
CUBE함수의 경우 표시된 인수들에 대한 계층별 집계를 구할 수 있으며, 이때 표시된 인수들 간에는 계층 구조인
ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌는 경우 행간에 정렬 순서는 바뀔 수 있어도 데이터 결과는 같다.
그리고 CUBE도 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 명시적으로 정렬 컬럼이 표시가 되어야 한다.
*/
--가. CUBE함수 이용
--GROUP BY ROLLUP(DNAME, JOB)조건에서 GROUP BY CUBE(DNAME, JOB) 조건으로 변경해서 수행한다.
SELECT CASE
GROUPING(DNAME) WHEN 1 THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE
GROUPING(JOB) WHEN 1 THEN 'All Jobs'
ELSE JOB
END AS JOB,
COUNT(*) "TOTAL EMPL",
SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE(DNAME, JOB);
/*
CUBE는 GROUPING COLUMNS이 가질 수 있는 모든 경우의 수에 대하여 SUBTOTAL을 생성하므로 GROUPING COLUMNS의 수가
N이라고 가정하면, 2의 N승 레벨의 SUBTOTAL을 생성하게 된다.
실행 경과에서 CUBE함수 사용으로 ROLLUP함수의 결과에다 업무별 집계까지 추가해서 출력할 수 있는데
ROLLUP 함수에 비해 업무별 집계를 표시한 5건의 레코드가 추가된 것을 확인할 수 있다.
*/
--나. UNION ALL 사용
--UNION ALL은 SET OPERATION내용으로, 여러 SQL문장을 연결하는 역할을 할 수 있다.
SELECT DNAME, JOB, COUNT(*)"TOTAL EMPL", SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
SELECT DNAME, 'ALL JOBS', COUNT(*) "TOTAL EMPL", SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'ALL DEPARTMENTS', JOB, COUNT(*)"TOTAL EMPL", SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB
UNION ALL
SELECT 'ALL DEPARTMENTS', 'ALL JOBS', COUNT(*)"TOTAL EMPL", SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO;
/*
따라서 CUBE함수를 사용하면 위에 처럼 네번이나 반복하는 부분은 간단하게 줄일 수 있다.
또한 가독성도 높아졌다.
*/
/*
----4. GROUPINBG SETS 함수
GROUPING SETS를 이용해 더욱 다양한 소계 집합을 만들 수 있다.
GROUP BY SQL문장을 여러 번 반복하지 않아도 원하는 결과를 쉽게 얻을 수 있다. GROUPING SETS에 표시된
인수들에 대한 개별 집계를 구할 수 있으며, 이때 표시된 인수들 간에는 계층 구조인 ROLLUP 과는 달리
평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
GROUPING SETS함수도 결과에 대한 정렬이 필요한 경우 ORDER BY 절에 명시적으로 정렬 컬럼이 표시가 되어야 한다.
*/
--예제: 일반 그룹함수를 이용하여 부서별, JOB별 인원수와 급여 합을 구하라.
SELECT DNAME, 'All Jobs' JOB, COUNT(*)"Total Empl", SUM(SAL)"Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'All Departments' DNAME, JOB, COUNT(*)"Total Empl", SUM(SAL)"Total Sal"
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
GROUP BY JOB;
/*
GROUPING SETS함수 사용시 UNION ALL을 사용한 일반 그룹함수를 사용한 SQL과 같은 결과를 얻을 수 있으며,
괄호로 묶은 집합 별로(괄호 안에는 계층구조가 아닌 하나의 데이터로 간주함) 집계를 구할 수 있다.
GROUPING SETS의 경우 일반 그룹함수를 이용한 SQL과 결과 데이터는 같으나 행들의 정렬 순서는 다를 수 있다.
*/
--GROUPING SETS함수를 이용하여 부서별, JOB별 인원수와 급여 합을 구하는데 GROUPING SETS의 인수들의 순서를 바꿔본다.
SELECT DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB, COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);
/*
GROUPING SETS 인수들은 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
(JOB과 DNAME의 순서가 바뀌었지만 결과는 같다.
*/
--부서-JOB-매니저 별 집계와 부서-JOB별 집계와, JOB-매니저 별 집계를 GROUPING SETS함수를 이용해서 구한다.\
SELECT DNAME, JOB, MGR, SUM(SAL)"TOTAL SAL"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS((DNAME, JOB, MGR), (DNAME, JOB), (JOB, MGR));
/*
실행결과에서 첫 번째 10건의 데이터는 (DANME, JOB, MGR)기준의 집계이며,
두 번째 8건의 데이터는 (JOB, MGR)기준의 집계이며
세 번째 9건의 데이터는 (DNAME, JOB)기준의 집계이다.
*/
[출처]
wiki.gurubee.net/pages/viewpage.action?pageId=27427791
'Programming' 카테고리의 다른 글
| [python] Simple web server (0) | 2022.08.18 |
|---|---|
| Compiling Common Lisp to an executable (0) | 2022.07.30 |
| SQL: ROLLUP 기본사용법 (0) | 2022.07.21 |
| (Oracle) COMPRESS를 이용한 자원의 효과적 활용 (0) | 2022.07.21 |
| [Oracle] 오라클 PARTITION BY 사용법 정리 (분석함수) (0) | 2022.07.20 |